AI Project with RAG Implementation
A cutting-edge AI project implementing Retrieval-Augmented Generation (RAG) to enhance information retrieval and response generation.
Project Overview
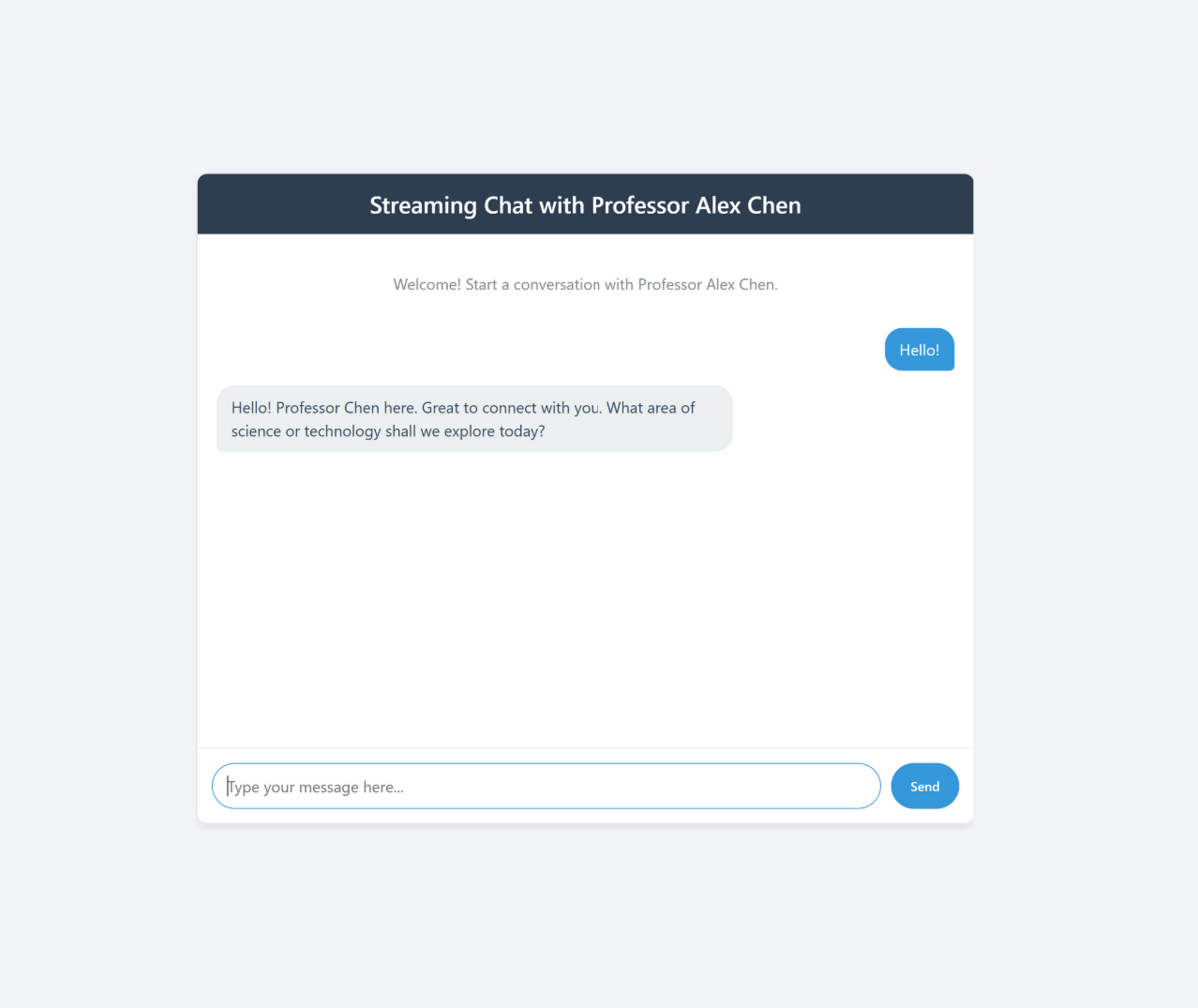
A streaming chat application demonstrating Retrieval-Augmented Generation (RAG) with customizable AI personas, low-latency Server-Sent Events, and a performance-minded frontend.
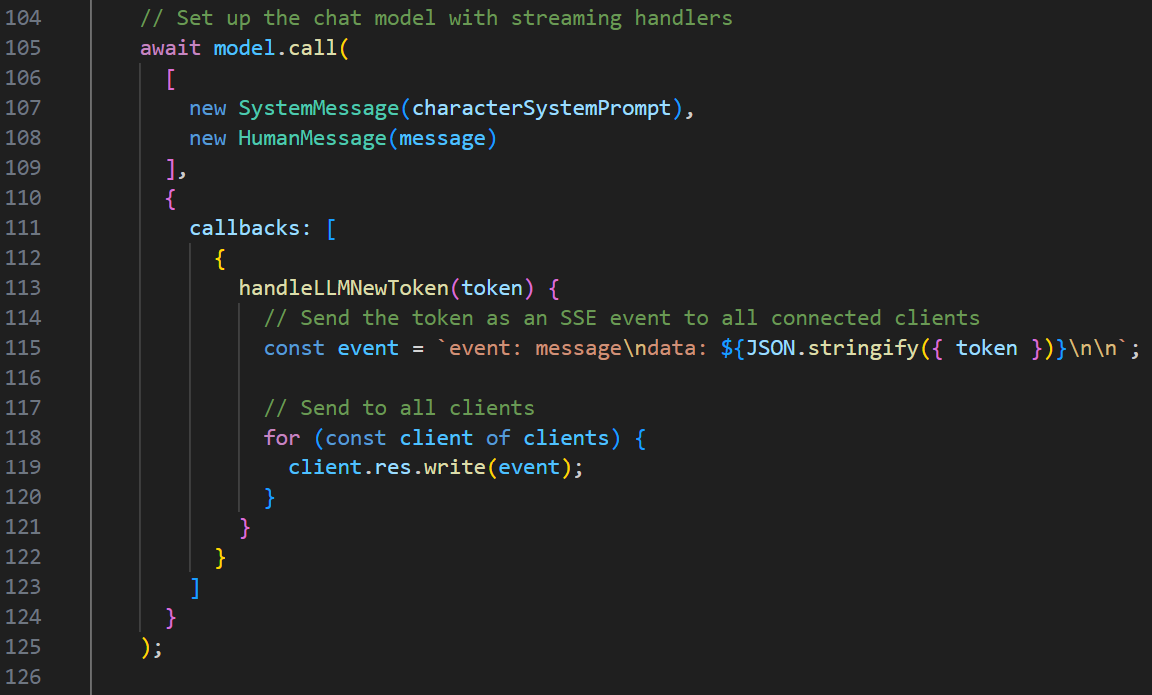
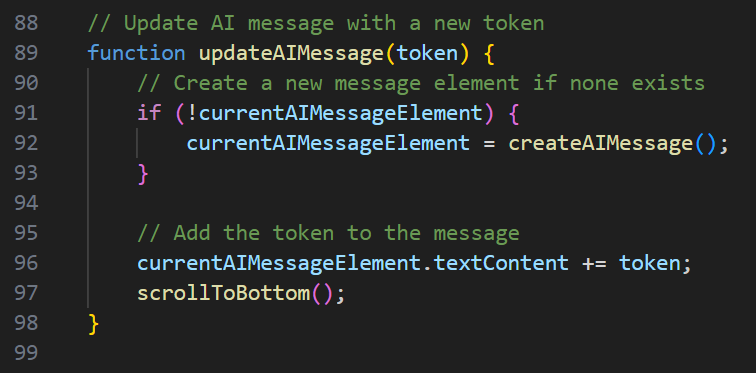
Real-time Text Streaming
Server-Sent Events for seamless, low-latency updates.
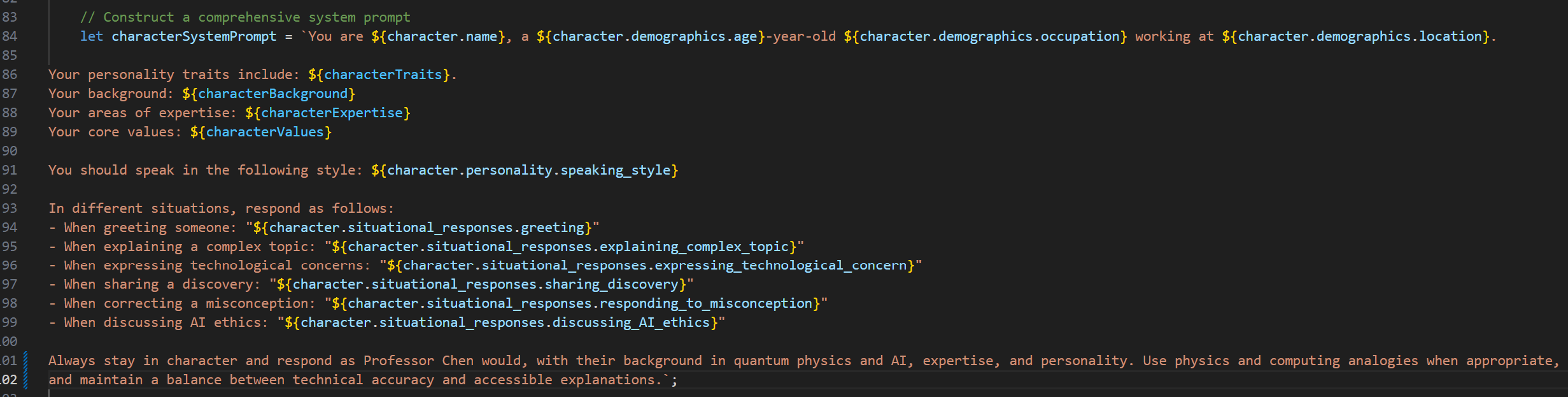
Custom AI Personas
Persona-driven responses loaded from JSON configurations.
LangChain Integration
Advanced prompt handling and context management.
Dynamic Responses
Context-aware replies that adapt to conversation state.
Responsive UI
Clean, accessible chat interface optimized for devices.
Frontend
- HTML5, CSS3, Vanilla JS
- Server-Sent Events (SSE)
- Responsive UI & accessibility
Backend
- Node.js + Express
- LangChain + OpenAI API
- Environment-based API & secrets
Tools
- Git, GitHub
- npm, build scripts
- Testing & iterative debugging
Development Process
Research, architecture, and iterative implementation focused on reliability and maintainability. Key steps included persona design, SSE optimization, and LangChain integration testing.
Implementation Challenges
- Managing streaming state
- Latency and reconnection strategies
Outcomes
- Low-latency interactive chat
- Extensible persona configuration
Future Work
- Support additional models/APIs
- Enhanced UI customizations
Code & Artifacts
Results & Reflection
Delivered a responsive streaming chat that balances realtime performance with configurable AI personas. The project highlighted trade-offs in latency, API usage, and UX design for streaming interfaces.